Building Immutable Cluster Images with LinuxKit
February 6, 2021 - 5 min read
kubernetes
docker
containerd
linuxkit
TL;DR
- Immutable infrastructure is a good option to avoid configuration drift
- LinuxKit can produce minimal images, speeding up deployments and improving security
- Containerized deployments can benefit from the above
One of the challenges of running large scale infrastructures is making sure nodes are kept consistent and up to date, avoiding configuration drift. One way of achieving this is relying on systems like CFEngine, Puppet or Chef, regularly (re)applying the expected configuration on the nodes (SnowFlakes). A limitation of this approach is that drift will only be spotted in areas defined under these tools’ control and for long lived instances it's common to find inconsistencies in other areas - practice tells us there will always be some.
An alternative is to rely on immutable infrastructure, where nodes (PhoenixServers) are launched from a base image and never changed. Updates are done directly on the base image (possibly created using the tools above, most often not) and nodes are recreated from scratch, ensuring any configuration drift is removed. It also improves reproducibility and makes deployments more predictable - including more reliable rollbacks when needed.
Uptime bragging rights will be lost, but probably not missed by many…
The latter is popular in containerized environments with the nodes being set with a small image containing only the minimal set of dependencies to launch additional service and application containers. Tools that explore this in the Kubernetes and container area include RancherOS, Flatcar (a fork from pre-RH CoreOS), Fedora CoreOS or GCP's Container-Optimized OS. This post looks at what can be done in LinuxKit, but the same layout is valid for the other tools.
LinuxKit
LinuxKit is a toolkit for building custom minimal, immutable Linux distributions.
It puts special focus on providing secure defaults, reproducibility and easy iteration. Images are built using containers for running containers - this even includes the kernel which is also distributed as an image. It relies on Notary to enforce trust by signing and verifying the images.
The layout is defined in yaml, here is an example:
kernel:
image: linuxkit/kernel:5.4.39
cmdline: "console=ttyS0"
init:
- linuxkit/init:a68f9fa0c1d9dbfc9c23663749a0b7ac510cbe1c
- linuxkit/runc:v0.8
- linuxkit/containerd:a4aa19c608556f7d786852557c36136255220c1f
- linuxkit/ca-certificates:v0.8
onboot:
- name: sysctl
image: linuxkit/sysctl:v0.8
- name: dhcpcd
image: linuxkit/dhcpcd:v0.8
command: ["/sbin/dhcpcd", "--nobackground", "-f", "/dhcpcd.conf", "-1"]
- name: metadata
image: linuxkit/metadata:v0.8
command: ["/usr/bin/metadata", "openstack"]
services:
- name: rngd
image: linuxkit/rngd:v0.8
- name: sshd
image: linuxkit/sshd:666b4a1a323140aa1f332826164afba506abf597
Each section handles the given image in a different way.
kernel is a special image with the kernel and any additional modules that get unpacked into root. You can find details on how kernel images are built here.
init contains images that get unpacked into the root filesystem, and should take care of all that is needed to get a functional containerd.
onboot images are run on containerd but before any other image, sequentially, and must succeed before the next image is run. Useful for things that need to be run or up before long lived services are launched.
services are long lived services running on containerd, with no defined launching order (meaning you might need logic to wait for resources to be available).
We can build the image with a single command:
$ linuxkit build -format qcow2-bios linuxkit.yml
$ ls -s linuxkit.qcow2
121288 linuxkit.qcow2
The final image is just over 120MB (vs 1.7GB of a Fedora Core image!).
In this case we include the additional metadata component to handle the node configuration in an OpenStack environment and rngd and sshd as long lived services, so the image could be even smaller - check here for the available pre-built containers, and here if you want to go ahead and turn your containerized service into a LinuxKit package.
Orchestration
Having a small base image has multiple advantages:
- Fewer components, easier to maintain, improved security
- Faster upgrades and efficient cluster auto scaling
- Reduced load on the network and storage
For a single or low number of workloads we could consider including all in one image, but on a large infrastructure running multiple heterogeneous workloads this is not practical. It would potentially make the image very big (breaking the purpose), updates on a single workload would require rebuilding and redeploying the full image, and with a single large image or multiple smaller images we still need some sort of orchestration.
A better match is to rely on a minimal image for the base components, and rely on Kubernetes (or other orchestrator) to handle the actual workloads. Kubernetes already does the job of ensuring the desired workload constraints are followed - Affinities, TopologyContraints, PodDisruptionBudgets, etc. - and is designed so nodes are disposable by default and can be recreated without an impact on the workloads (minus stateful workloads).
We end up with something like this…
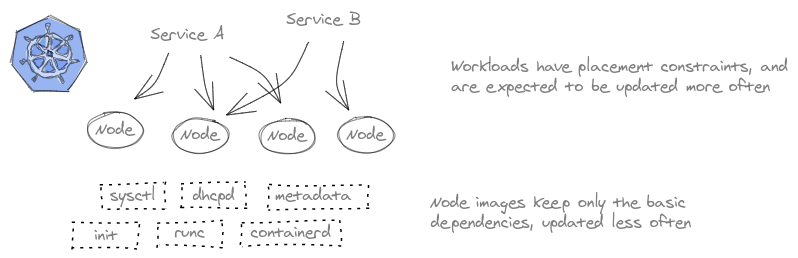
Both nodes and containers are handled as immutable and disposable units, but we get finer granularity on the deployment where needed by running the workloads in containers. A kernel upgrade means a rollout of a new base image across the cluster (recreating the nodes), but a new release of a single service only requires recreating the corresponding service containers.
In addition to the benefits described above, relying on immutable infrastructure also poses a few challenges - the first debug session can be quite frustating when apt-get install and similar is not possible. But the notion of everything is a container picks up quickly, and keeping close by an image with all required tools (netstat, tcpdump, and other good friends) offers an even better way to easily and quickly debug issues on individual nodes - and again, only when really needed.